Evidence Engine: Guess the Winner, Then Run the Real Numbers
An interactive companion to Self-Service Workflow that asks you to guess which design won, then replays the real 53% to 96% outcome instead of telling you upfront.
- Role
- Designer & Developer
- Timeline
- 2026
- Tools
- Astro, vanilla JS
- Team
- Solo
This builds directly on the real numbers from Self-Service Workflow: a redesign that scaled self-service completion from 53% to 96%. That case study tells you what happened. This one asks you to guess first.
The Problem
“Evidence over taste” is easy to say and hard to feel. Most people, including most designers, read a before/after case study, glance at the after screen, and assume it was the obviously better choice all along. That hindsight is cheap. It doesn’t tell you whether you’d have actually picked the winner before you knew the outcome, which is the only moment a real design decision happens in.
The Process
Design A
- Multi-touch process
- Manual back-and-forth with asset owners
- Unclear ownership on requests
- Slow, confusing flow
Design B
- One guided change-order pattern
- Select the asset, a side panel opens
- Dropdown of available metadata changes
- Add fields, submit, get confirmation
Which one do you think performed better?
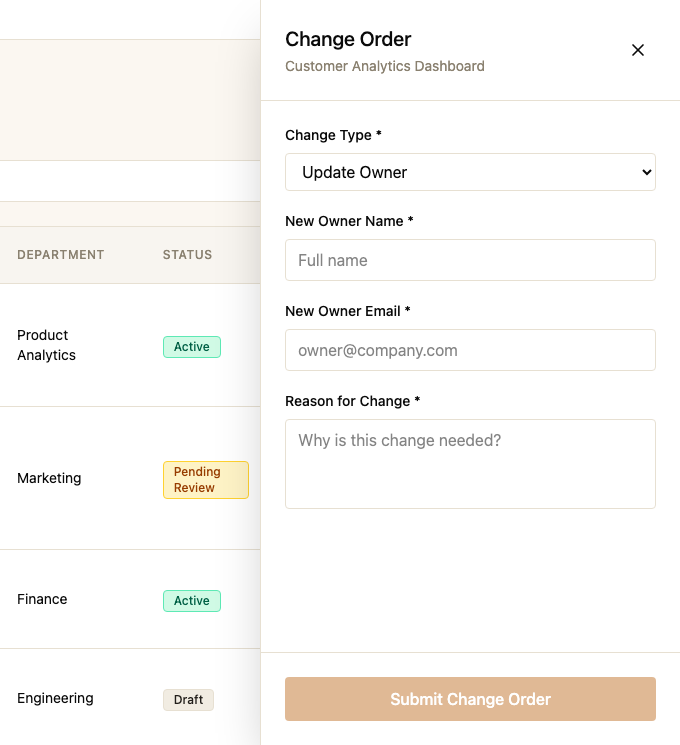
Design B won because it redesigned the flow, not the screens: fewer steps to cross, and no ambiguity left about who owned a request. Design A's screens weren't broken individually. The problem was how many of them, and how much uncertainty, a user had to get through.
Two real design states, described in plain, symmetrical text: no screenshots, no visual polish tipping the scale. You guess which one performed better, lock it in, then run the simulation. A brief flicker through some fake intermediate numbers, then the real ones land: the actual completion swing, the actual secondary metrics, and the actual screenshot, all from Self-Service Workflow’s real, already-completed outcome.
The Decision
This isn’t a live experiment, and it doesn’t pretend to be one. There’s no real traffic behind it, no statistical significance test, and no new data being generated. It’s a simulated replay of a result that already happened, built to recreate the shape of an A/B reveal: the suspense of not knowing yet, using numbers that are otherwise just sitting flat on a case study page. The “running the simulation” moment is cosmetic, a slot-machine settle, not a statistical engine.
Keeping the two designs symmetrical before the guess was the non-negotiable part. The moment Design B got a screenshot and Design A didn’t, the guess would stop being a guess.
The Outcome
- A standalone, cross-linked entry that asks visitors to predict an outcome before revealing it, instead of just narrating one
- The same real numbers as Self-Service Workflow: completion scaling 53% to 96%, 100% owner attribution on requests, and a 25% cut in manual support tickets
- The real change-order screenshot, held back until after the guess, so it can’t bias the choice
Reflection
The honest version of this project is a little less flattering than a slicker one would be: it isn’t proof of anything new, it’s a replay of evidence that already existed. What it’s actually testing is whether the reasoning in Self-Service Workflow’s win holds up when you have to commit to a side before you’re told the answer. The original case study’s own conclusion was that the fix was the flow, not the screens: fewer steps, no ambiguity about who owned a request. Guessing first is just a way of making that conclusion land instead of just reading it.